 본 연구실에서는 사용자의 의도를 뇌파만으로 읽어 내는 기술을 개발하고 있습니다.
본 연구실에서는 사용자의 의도를 뇌파만으로 읽어 내는 기술을 개발하고 있습니다.
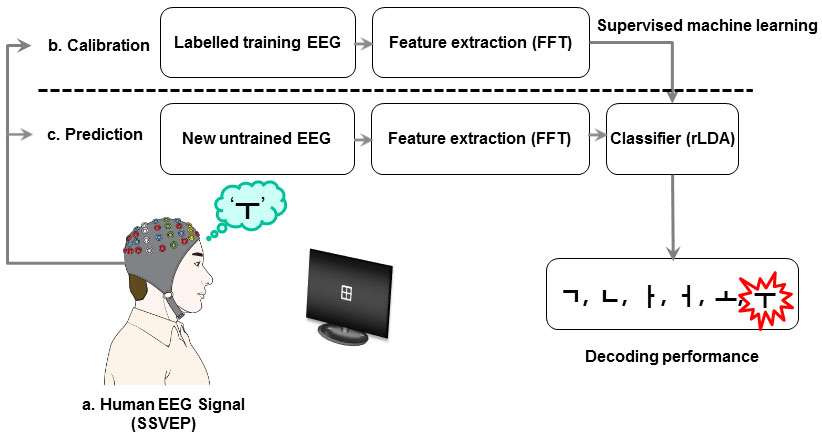
모니터에서 깜박이는 '田' 모양을 사용해서, 눈동자를 움직이지 않고, 6개의 글자('ㄱ','ㄴ','ㅏ','ㅓ','ㅗ','ㅜ') 중에서 무엇을 생각하고 있는지를 뇌파(EEG)만으로 구분하는 Brain-Machine Interface 연구가,
MULTIDISCIPLINARY SCIENCES 분야 IF 상위 10%(57개 저널 중에 5위)이며, Nature에서 발간하는 ‘Scientific Reports’에 온라인 게재 되었습니다 (2016년 11월 3일). Shortened URL: http://rdcu.be/mj2w
이 기술은 현재 국내 특허가 등록되어 있고 (등록번호: 10-1431203), 미국 특허도 출원된 상태입니다 (US Patent application No. 14/884,972).
Title: Decoding of top-down cognitive processing for SSVEP-controlled BMI
Abstract:
We present a fast and accurate non-invasive brain-machine interface (BMI) based on demodulating steady-state visual evoked potentials (SSVEPs) in electroencephalography (EEG). Our study reports an SSVEP-BMI that, for the first time, decodes primarily based on top-down and not bottom-up visual information processing. The experimental setup presents a grid-shaped flickering line array that the participants observe while intentionally attending to a subset of flickering lines representing the shape of a letter. While the flickering pixels stimulate the participant’s visual cortex uniformly with equal probability, the participant’s intention groups the strokes and thus perceives a ‘letter Gestalt.’ We observed decoding accuracy of 35.81% (up to 65.83%) with a regularized linear discriminant analysis; on average 2.05-fold, and up to 3.77-fold greater than chance levels in multi-class classification. Compared to the EEG signals, an electrooculogram (EOG) did not significantly contribute to decoding accuracies. Further analysis reveals that the top-down SSVEP paradigm shows the most focalised activation pattern around occipital visual areas; Granger causality analysis consistently revealed prefrontal top-down control over early visual processing. Taken together, the present paradigm provides the first neurophysiological evidence for the top-down SSVEP BMI paradigm, which potentially enables multi-class intentional control of EEG-BMIs without using gaze-shifting.
Figure 1. Schema for the workflow of a top-down SSVEP paradigm for multi-class decoding BMI technology. (a) EEG recording, (b) Calibration by supervised machine learning from training EEG trials, and (c) Decoding process on test EEG trials to correctly predict participant perception. When a participant conceives the letter ‘⊤’, the corresponding flickering line composite on the grid-shaped array is subsequently attended and a classification algorithm using feature extraction (i.e., rLDA), calibrated through supervised machine learning, enables the successful decoding of the originally conceived letter ‘⊤’. FFT stands for ‘fast Fourier transform’ and rLDA represents ‘regularized linear discriminant analysis’.